パッケージの概要
mlbenchには、機械学習モデルの性能を比較・評価するベンチマーク課題用のデータセット、およびデータを生成するための関数が用意されています。
データセットは、例えばBostonHousing等の有名なデータセットや、UCIリポジトリ[1] (カリフォルニア大学アーバイン校が公開している機械学習データセットリポジトリ)の一部のデータセット等が含まれています。
また、ベンチマーク課題用のテストデータを生成する関数には、例えば複数クラスの2次元正規分布を生成するmlbench.2dnormals関数や、螺旋データを生成するmlbench.spiral関数等、様々な種類の関数が用意されています。
なお、mlbenchに用意されているこれらのデータ生成用の関数は、mlbench.[データを示す名称]という形式の関数名になっています。一方、mlbenchに格納されているデータセットそのものは、BostonHousingやZooのように、mlbench.がついておらず大文字から始まる名称なので、データセットとデータ生成関数は名前で区別することができます。
パッケージの使用例
データセット
mlbenchには、様々なベンチマーク課題用のデータセットが用意されています。 データセットは以下のように、データセット名を指定してdata.frameとしてロードすることができます。
library(mlbench)
data("BostonHousing", package = "mlbench")
str(BostonHousing)
'data.frame': 506 obs. of 14 variables:
$ crim : num 0.00632 0.02731 0.02729 0.03237 0.06905 ...
$ zn : num 18 0 0 0 0 0 12.5 12.5 12.5 12.5 ...
$ indus : num 2.31 7.07 7.07 2.18 2.18 2.18 7.87 7.87 7.87 7.87 ...
$ chas : Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 1 1 1 ...
$ nox : num 0.538 0.469 0.469 0.458 0.458 0.458 0.524 0.524 0.524 0.524 ...
$ rm : num 6.58 6.42 7.18 7 7.15 ...
$ age : num 65.2 78.9 61.1 45.8 54.2 58.7 66.6 96.1 100 85.9 ...
$ dis : num 4.09 4.97 4.97 6.06 6.06 ...
$ rad : num 1 2 2 3 3 3 5 5 5 5 ...
$ tax : num 296 242 242 222 222 222 311 311 311 311 ...
$ ptratio: num 15.3 17.8 17.8 18.7 18.7 18.7 15.2 15.2 15.2 15.2 ...
$ b : num 397 397 393 395 397 ...
$ lstat : num 4.98 9.14 4.03 2.94 5.33 ...
$ medv : num 24 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 ...
以下は格納されているデータセットの一覧です。(バージョン2.1.5時点です。)
クラス分類用のデータや回帰用のデータ、特徴量が連続変数のデータやカテゴリ変数のデータ、クラスに偏りがあるデータなど、様々な種類の機械学習のベンチマーク課題に使用できるようなデータが格納されています。 各データのカラムやデータソース等の詳細は、mlbenchのリファレンスをご参照ください。
データ生成関数
mlbenchには前項で紹介したデータセットに加え、ベンチマーク課題用のデータを自ら生成するための関数も用意されています。
以下は、指定したクラス数のクラスごとに、2次元空間上で正規分布するデータを生成する、mlbench.2dnormalsの使用例です。 これらの生成関数によるデータは、R標準のS3 classという機能を用いて、as.data.frame関数とplot関数が適切に動作するように実装されています。 すなわち、List形式で返される生成データを引数として、as.data.frame関数によるデータフレームへ変換、およびplot関数による生成データの種類に応じたグラフのプロットができるようになっています。
# 乱数シードの設定
set.seed(123)
# 2次元正規分布データの生成
## cl=2が2クラスを意味する
## デフォルトでは原点を中心に、半径r=(cl)^(1/2)の円上に各クラスの中心を配置する
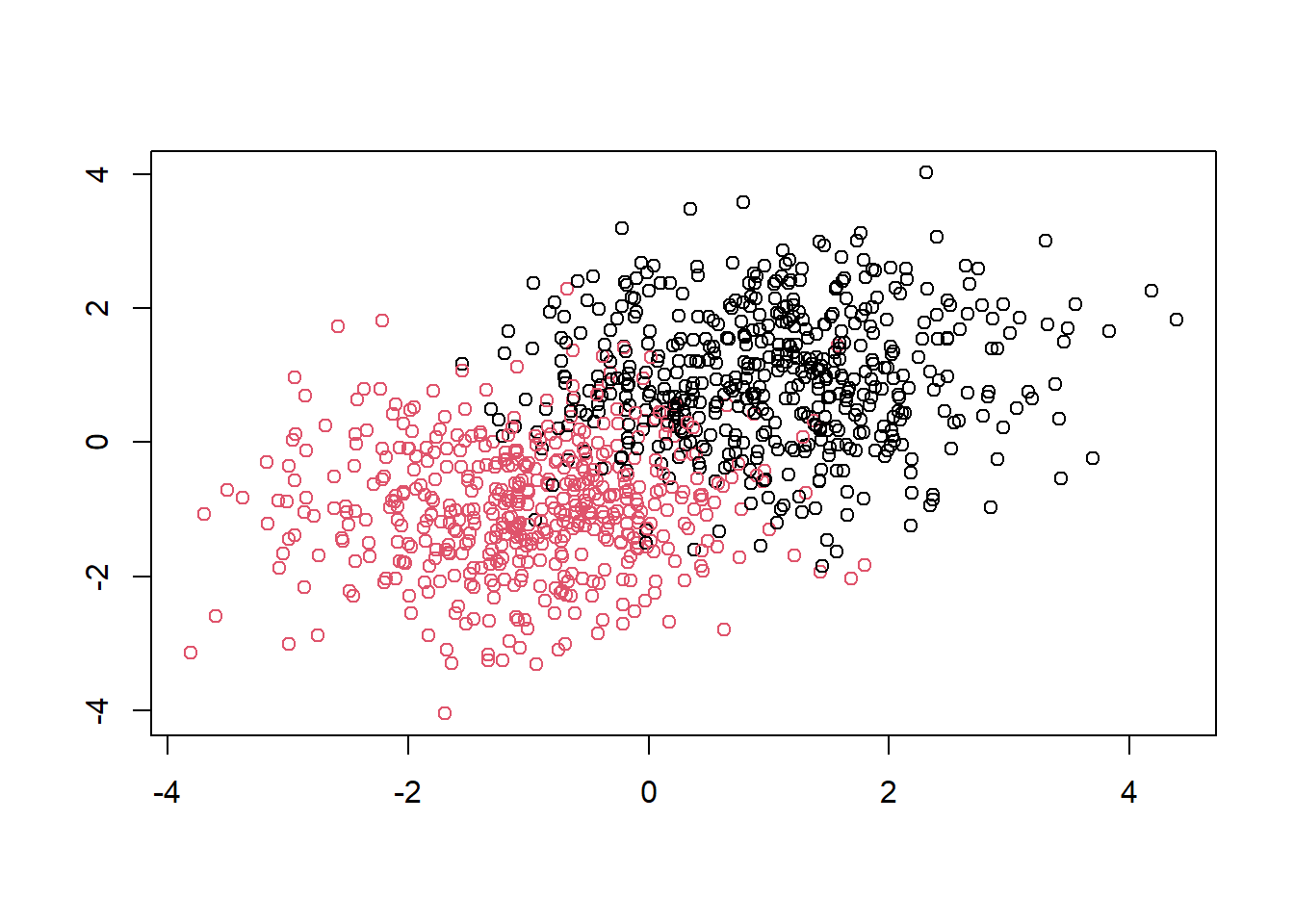
p <- mlbench.2dnormals(n=1000, cl=2, sd=1)
# 生成したデータはmlbench.2dnormals classのList形式
str(p)
List of 2
$ x : num [1:1000, 1:2] 0.3981 0.0063 2.0268 -0.2489 -0.5092 ...
$ classes: Factor w/ 2 levels "1","2": 1 1 1 2 1 2 2 2 1 1 ...
- attr(*, "class")= chr [1:2] "mlbench.2dnormals" "mlbench"
# data.frameへの変換
str(as.data.frame(p))
'data.frame': 1000 obs. of 3 variables:
$ x.1 : num 0.3981 0.0063 2.0268 -0.2489 -0.5092 ...
$ x.2 : num 0.179 0.6927 0.0979 -0.3729 2.1204 ...
$ classes: Factor w/ 2 levels "1","2": 1 1 1 2 1 2 2 2 1 1 ...
# mlbench.2dnormals classのplot
plot(p)
さらに、mlbenchの生成データに対して適用可能なベイズ識別器、bayesclass関数が用意されています。内部的には、引数として渡す生成データの種類によって、適切な識別関数の実装が呼び出されています。
以下は、mlbench.2dnormalsで生成した2クラス分類用のデータ対する、bayesclass関数による分類結果をプロットしています。 mlbench.2dnormalsの生成データの場合、いずれのクラスも同分散の2次元正規分布に従うため、個々のデータは、各クラスの正規分布の中心(期待値)のうち、最も距離の近い中心を持つクラスへと分類されることになります。 そのため、上のグラフで示した真のクラスと、下図の分類結果とを比較すると、グラフ中央付近の両クラスのデータが重なる領域では、誤分類が発生していることがわかります。
plot(p$x, col=as.numeric(bayesclass(p)))
上で紹介したmlbench.2dnormals以外にも、mlbenchでは様々なデータ生成用の関数が用意されています。 以下ではいくつかの例をplotしています。 これらの例に挙げたもの以外を含む、関数の一覧や各関数の詳細については、mlbenchのリファレンスをご参照ください。
Spiral
plot(mlbench.spirals(n=200, sd=0.05))
Circle
plot(mlbench.circle(n=1000))
Shapes
plot(mlbench.shapes(n=1000))
Smiley
plot(mlbench.smiley(n=1000))