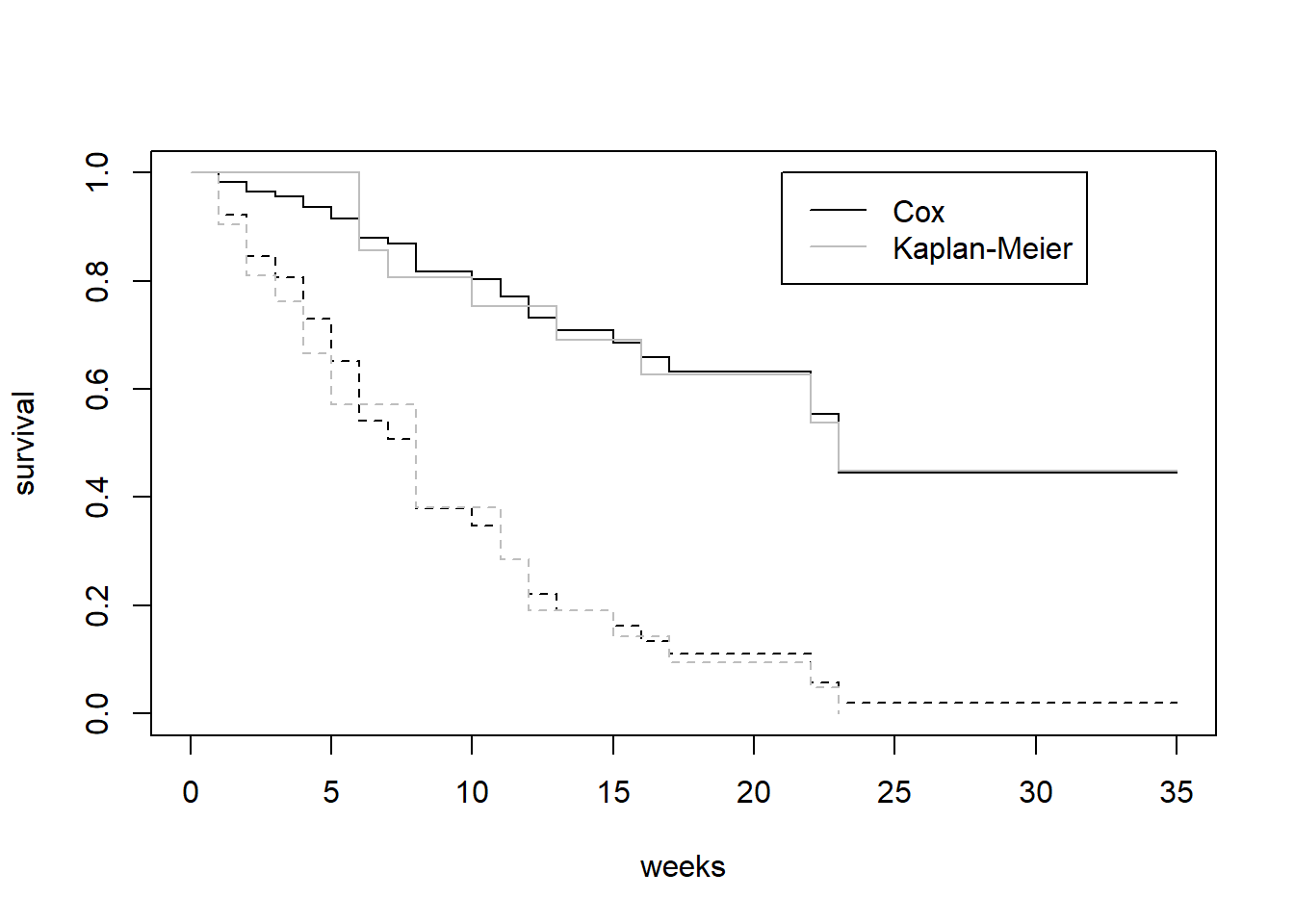library(survival)
x <- c(1, 2, 3, 3, 4, 5, 5) # 死亡等の発生時刻
c <- c(4, 1, 2, 4, 4, 6, 2) # 打ち切りの発生時刻
t <- pmin(x, c) # 観測されたイベントの発生時刻
d <- t == x # 観測されたイベントの種類(死亡等かどうか)
Surv(time = t, event = d)[1] 1 1+ 2+ 3 4 5 2+# + は打ち切られたことを示す。survivalは R で生存時間解析を行うためのパッケージで、生存関数やハザード関数に関する推定・検定などを行うための機能が実装されています。
survival パッケージでは、Surv() 関数を用いて生存時間解析用のデータセット(“Surv” オブジェクト)を作成することができます。“Surv” オブジェクトは、生存時間(観察時間)と打ち切り指標を表すベクトルの組をもとにして作成されます。
m 人の対象者 i=1,2,..., n について、死亡等(死亡や要介護状態への移行などの特定の事由による脱退)と打ち切り(それ以外の事由による脱退または観察の終了)という2種類のイベントが記録されているとします。死亡等の発生時間を X_i 、打ち切りの発生時間を C_i とすると、各個人 i について、いずれか早い方の発生時間 T_i = \min\left(X_i, C_i\right) が観測されます。生存時間解析においては、死亡等と打ち切りどちらが観測されたかを表す変数を D_i として、\left\{\left(T_i, D_i\right)\right\}_{i=1}^n を収集したデータセットが分析の対象となります。
library(survival)
x <- c(1, 2, 3, 3, 4, 5, 5) # 死亡等の発生時刻
c <- c(4, 1, 2, 4, 4, 6, 2) # 打ち切りの発生時刻
t <- pmin(x, c) # 観測されたイベントの発生時刻
d <- t == x # 観測されたイベントの種類(死亡等かどうか)
Surv(time = t, event = d)[1] 1 1+ 2+ 3 4 5 2+# + は打ち切られたことを示す。survfit() 関数を用いると、“Surv” オブジェクトに基づいて生存関数 S(t) に関する カプラン・マイヤー(Kaplan-Meier)推定を行うことができます。カプラン=マイヤー推定では、S(t) を下式によって推定します。
\hat{S}(t) = \prod\limits_{k:\;t_k{\le}t}\left(1-\frac{d_k}{n_k}\right)
ここで、t_k はイベントの発生時刻、d_k は時点 t_k における死亡等の発生数 n.event、n_k は時点 t_k の直前に残存している対象者数 n.risk を表します。
sample.sf <- survfit(Surv(t, d) ~ 1)
summary(sample.sf)Call: survfit(formula = Surv(t, d) ~ 1)
time n.risk n.event survival std.err lower 95% CI upper 95% CI
1 7 1 0.857 0.132 0.6334 1
3 3 1 0.571 0.249 0.2429 1
4 2 1 0.286 0.237 0.0561 1
5 1 1 0.000 NaN NA NAplot(sample.sf)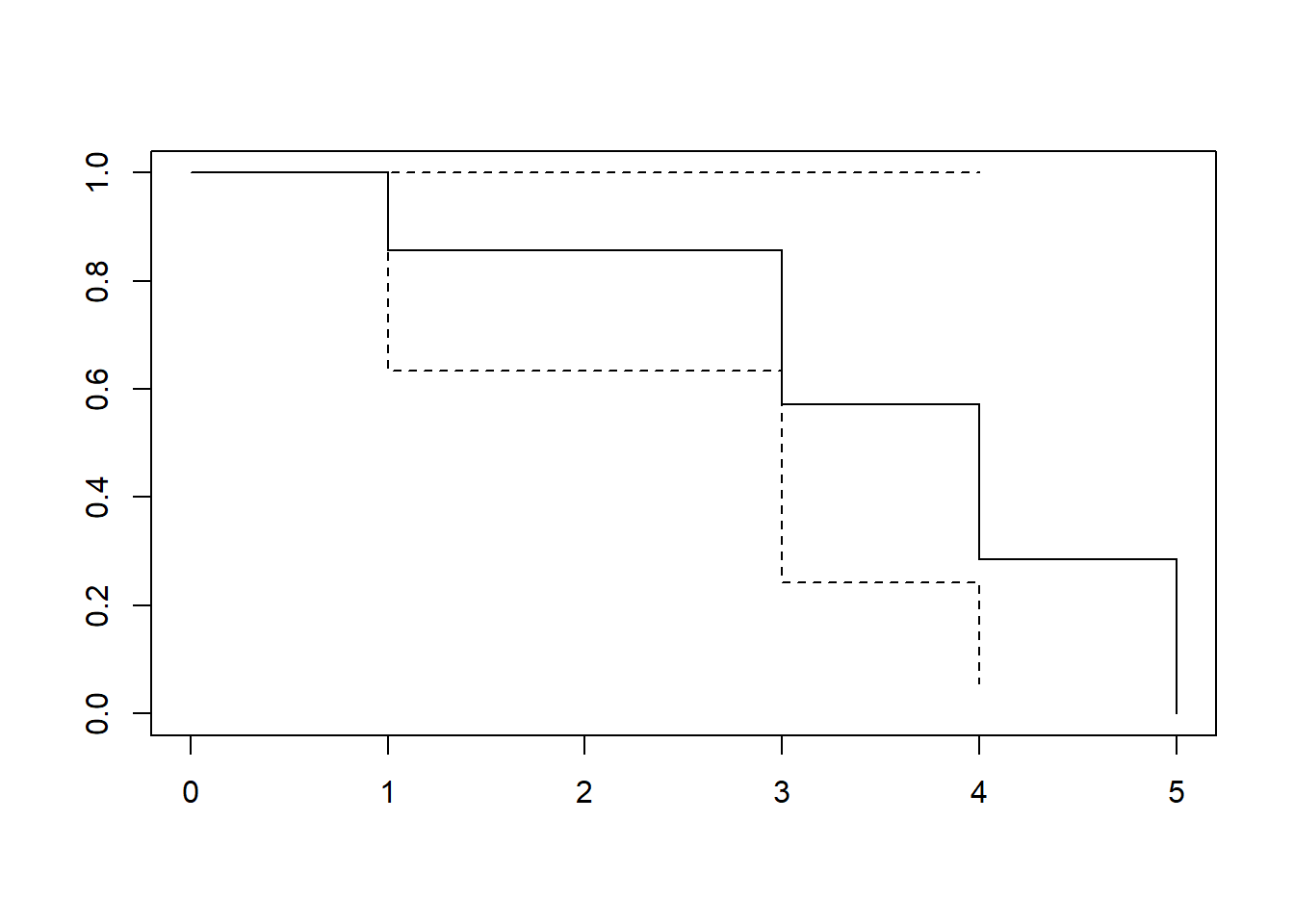
生存関数と密接な関係にあるのがハザード関数です。ハザード関数 \lambda(t) は、時点 t まで生存したという条件のもとで、次の瞬間に死亡等が発生する確率密度を表し、「瞬間の死亡率」と解釈できます。そして、ハザード関数を 0 から特定の時点 t まで積分したものを累積ハザード関数 H(t) と呼びます。
H(t)=\int_0^t{\lambda(u)}du ネルソン・アーレン(Nelson-Aalen)推定量は、この累積ハザード関数をノンパラメトリックに推定する手法です。推定式は以下のようになります。
\hat{H}(t) = \sum\limits_{k:\;t_k{\le}t}\frac{d_k}{n_k}
この式は、各時点における「リスク集団に対するイベント数の比(瞬間的なハザードの推定値)」を足し合わせたものであり、累積ハザードを直感的に表現しています。“survfit” オブジェクトの n.event と n.risk を用いることで、ネルソン⁼アーレン推定量を以下のように計算できます。
# 累積ハザード関数の Nelson-Aalen 推定量
data.frame(
sample.sf$time, # イベント発生時刻
cumsum(sample.sf$n.event / sample.sf$n.risk) # 時点ごとの発生率の累積和
) sample.sf.time cumsum.sample.sf.n.event.sample.sf.n.risk.
1 1 0.1428571
2 2 0.1428571
3 3 0.4761905
4 4 0.9761905
5 5 1.9761905性別や治療の有無などを表す特徴量によって対象者を2群に分けられるときは、formula の ~ の右側にその特徴量を指定することで、生存関数の推定をグループごとに行うことができます。
ここでは、MASS パッケージに収録されている gehan データセットを利用します。これは、白血病患者の寛解期間を比較した臨床試験のデータです。
data(gehan, package = "MASS")
str(gehan)'data.frame': 42 obs. of 4 variables:
$ pair : int 1 1 2 2 3 3 4 4 5 5 ...
$ time : int 1 10 22 7 3 32 12 23 8 22 ...
$ cens : int 1 1 1 1 1 0 1 1 1 1 ...
$ treat: Factor w/ 2 levels "6-MP","control": 2 1 2 1 2 1 2 1 2 1 ...time: 寛解が終了するまでの週数(イベント時間)。
cens: 寛解が終了した(イベント発生)か、観察が打ち切られたかを示す指標。1がイベント発生、0が打ち切りを意味します。
treat: 処置の種類を示す因子型変数。
plot(survfit(Surv(time, cens) ~ treat, data = gehan),
lty = 1:2, xlab = "weeks", ylab = "survival")
legend("topright", levels(gehan$treat), lty = 1:2)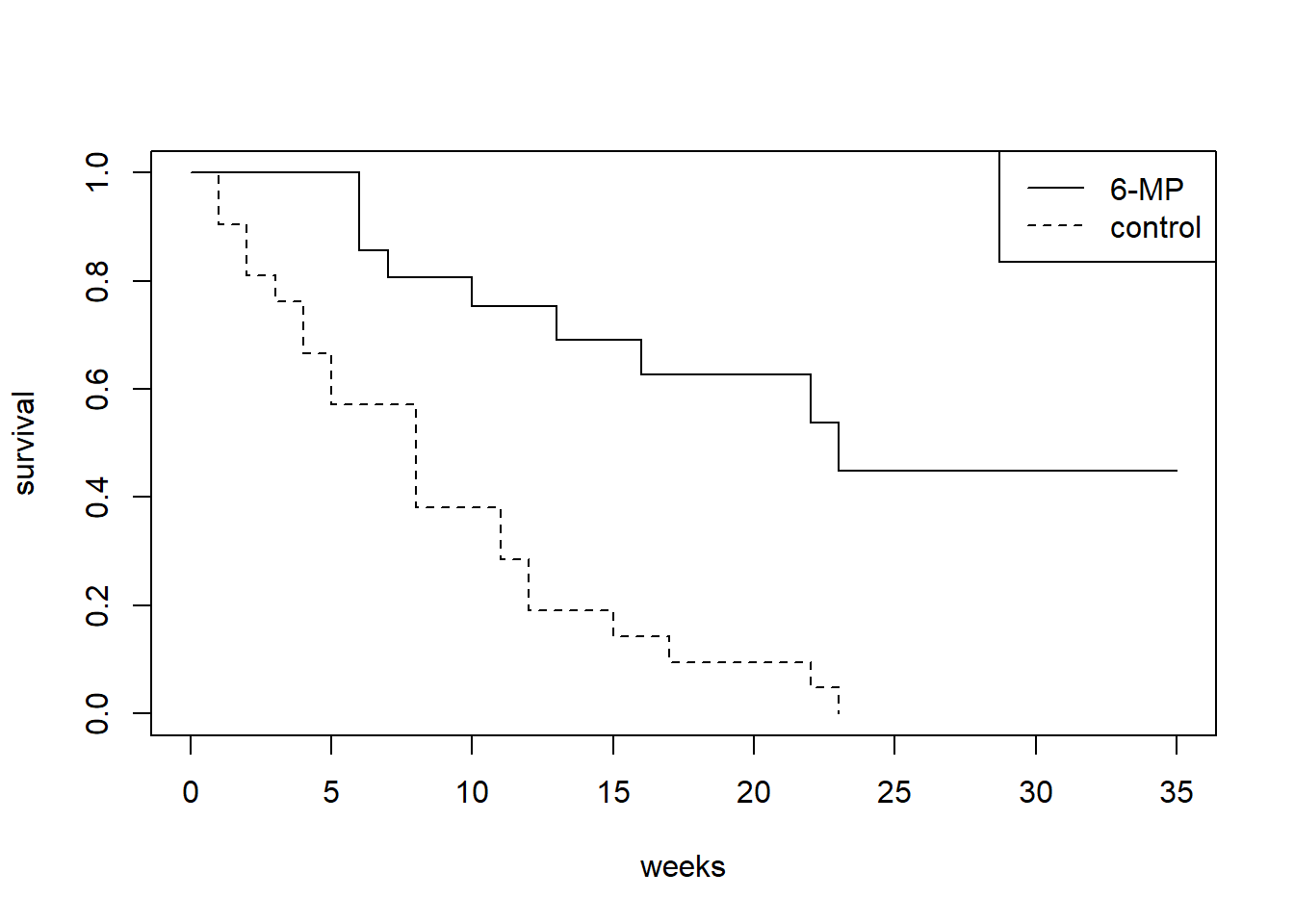
2群の差についての統計的検定として、survdiff() 関数を用いてログランク検定を行うことができます。ログランク検定では、生存関数が同じであるという帰無仮説がデータによってテストされます。
survdiff(Surv(time, cens) ~ treat, data = gehan)Call:
survdiff(formula = Surv(time, cens) ~ treat, data = gehan)
N Observed Expected (O-E)^2/E (O-E)^2/V
treat=6-MP 21 9 19.3 5.46 16.8
treat=control 21 21 10.7 9.77 16.8
Chisq= 16.8 on 1 degrees of freedom, p= 4e-05 survreg() 関数を用いることで、生存関数 S(x) の形状として指数分布、ワイブル分布、対数ロジスティック分布などを仮定したパラメトリック推定を行うことができます。これは加速故障時間(AFT)モデルの一種としてモデル化されます。
str(kidney)'data.frame': 76 obs. of 7 variables:
$ id : num 1 1 2 2 3 3 4 4 5 5 ...
$ time : num 8 16 23 13 22 28 447 318 30 12 ...
$ status : num 1 1 1 0 1 1 1 1 1 1 ...
$ age : num 28 28 48 48 32 32 31 32 10 10 ...
$ sex : num 1 1 2 2 1 1 2 2 1 1 ...
$ disease: Factor w/ 4 levels "Other","GN","AN",..: 1 1 2 2 1 1 1 1 1 1 ...
$ frail : num 2.3 2.3 1.9 1.9 1.2 1.2 0.5 0.5 1.5 1.5 ...sreg <- survreg(Surv(time, status) ~ as.factor(sex),
data = kidney, dist = "weibull")
sregCall:
survreg(formula = Surv(time, status) ~ as.factor(sex), data = kidney,
dist = "weibull")
Coefficients:
(Intercept) as.factor(sex)2
4.0946906 0.9866032
Scale= 1.106087
Loglik(model)= -336.6 Loglik(intercept only)= -340.9
Chisq= 8.61 on 1 degrees of freedom, p= 0.00334
n= 76 AFT モデルとして推定されたパラメータを、R の標準的なワイブル分布関数 pweibull() で利用できる形状 shape と尺度 scale パラメータに変換します。
shape <- 1 / sreg$scale # 形状パラメータ
scaleM <- exp(coef(sreg)[1]) # 尺度パラメータ
scaleF <- exp(coef(sreg)[1] + coef(sreg)[2])
# 比較のために Kaplan-Meier 推定値をプロットする
sfit <- survfit(Surv(time, status) ~ as.factor(sex), data = kidney)
plot(sfit, lty = 1:2)
# Weibull分布モデルのグラフ
curve(1 - pweibull(x, shape, scaleM),
add = TRUE, col = "darkcyan")
curve(1 - pweibull(x, shape, scaleF),
add = TRUE, col = "darkred", lty = 2)
legend("topright", c("male", "female"),
lty = 1:2, bty = "n")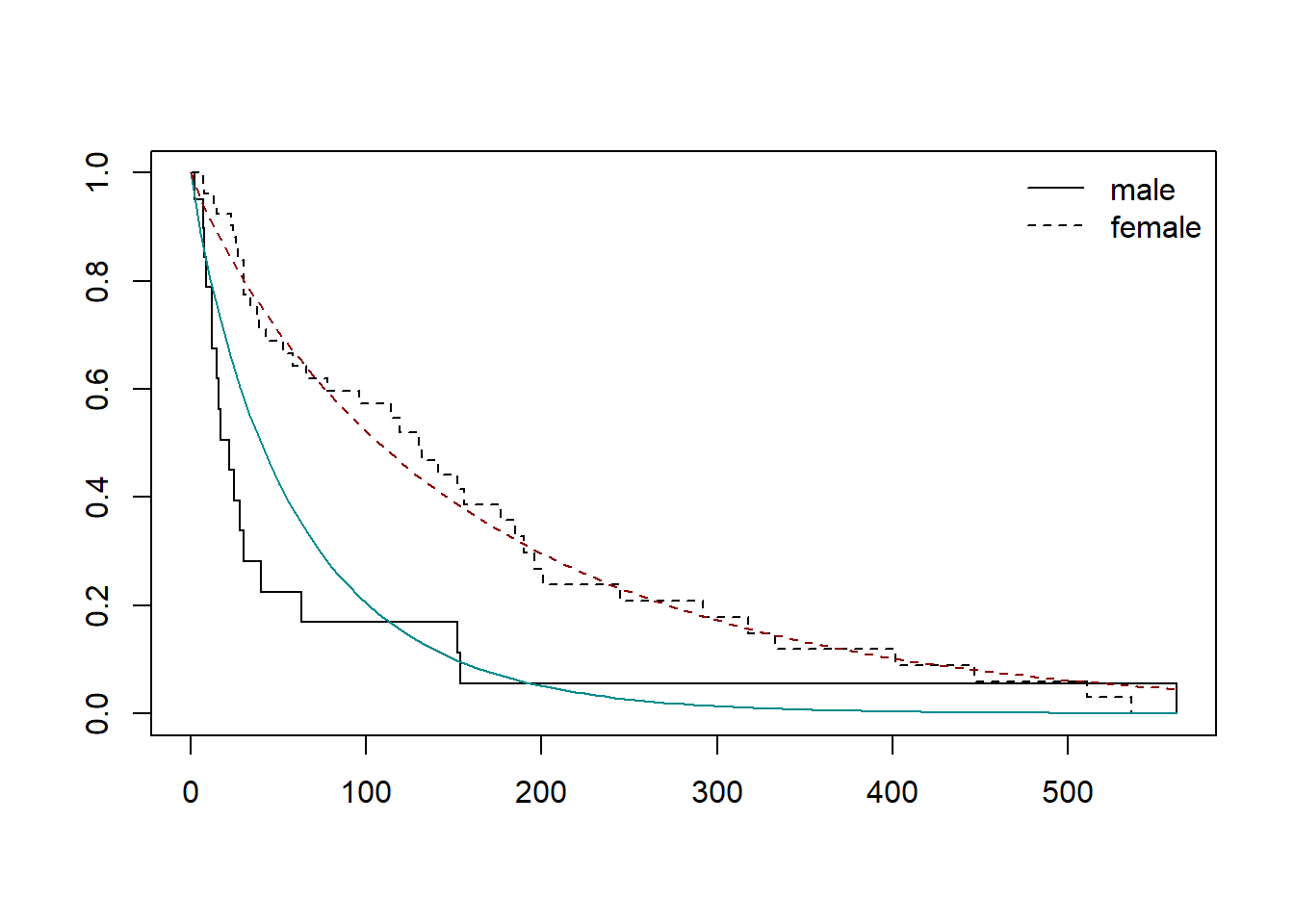
# パラメータの確認
cat(sprintf(
"shape: %.4f\nscale(male): %.4f\nscale(female): %.4f",
round(shape, 4), round(scaleM, 4), round(scaleF, 4))
)shape: 0.9041
scale(male): 60.0208
scale(female): 160.9822coxph() 関数を用いることで、Cox比例ハザード回帰モデル(Cox proportional hazards regression model)を構築することができます。
Kaplan-Meier推定では集団ごとにデータを分けることで生存関数を推定しましたが、Cox比例ハザードモデルでは、個人ごとのハザード関数を説明変数(共変量)Z に基づく線形予測子を用いて以下の式のようにモデル化し、回帰係数を一種の最尤法で推定します。
\lambda_i(t; Z)=\lambda_0(t)\ exp({\beta}^{T}Z)
比例ハザードモデルは、ベースラインハザード関数(潜在基礎ハザード関数) \lambda_0(t) の部分にノンパラメトリックな仮定を残しつつ、相対ハザード exp(\beta^TZ) の部分をパラメトリックにモデル化し、推定することから、セミパラメトリックモデルに分類されます。
summary(gehan.cox <- coxph(Surv(time, cens) ~ treat, gehan))Call:
coxph(formula = Surv(time, cens) ~ treat, data = gehan)
n= 42, number of events= 30
coef exp(coef) se(coef) z Pr(>|z|)
treatcontrol 1.5721 4.8169 0.4124 3.812 0.000138 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
treatcontrol 4.817 0.2076 2.147 10.81
Concordance= 0.69 (se = 0.041 )
Likelihood ratio test= 16.35 on 1 df, p=5e-05
Wald test = 14.53 on 1 df, p=1e-04
Score (logrank) test = 17.25 on 1 df, p=3e-05# 対照群"control"のハザード関数は、処置群"6MP"の4.82倍
Z <- data.frame(treat = levels(gehan$treat))
plot(survfit(gehan.cox, Z), lty = 1:2, xlab = "weeks", ylab = "survival")
lines(survfit(Surv(time, cens) ~ treat, gehan), lty = 1:2, col = "gray")
legend(21, 1, c("Cox", "Kaplan-Meier"), lty = 1, col = c("black", "gray"))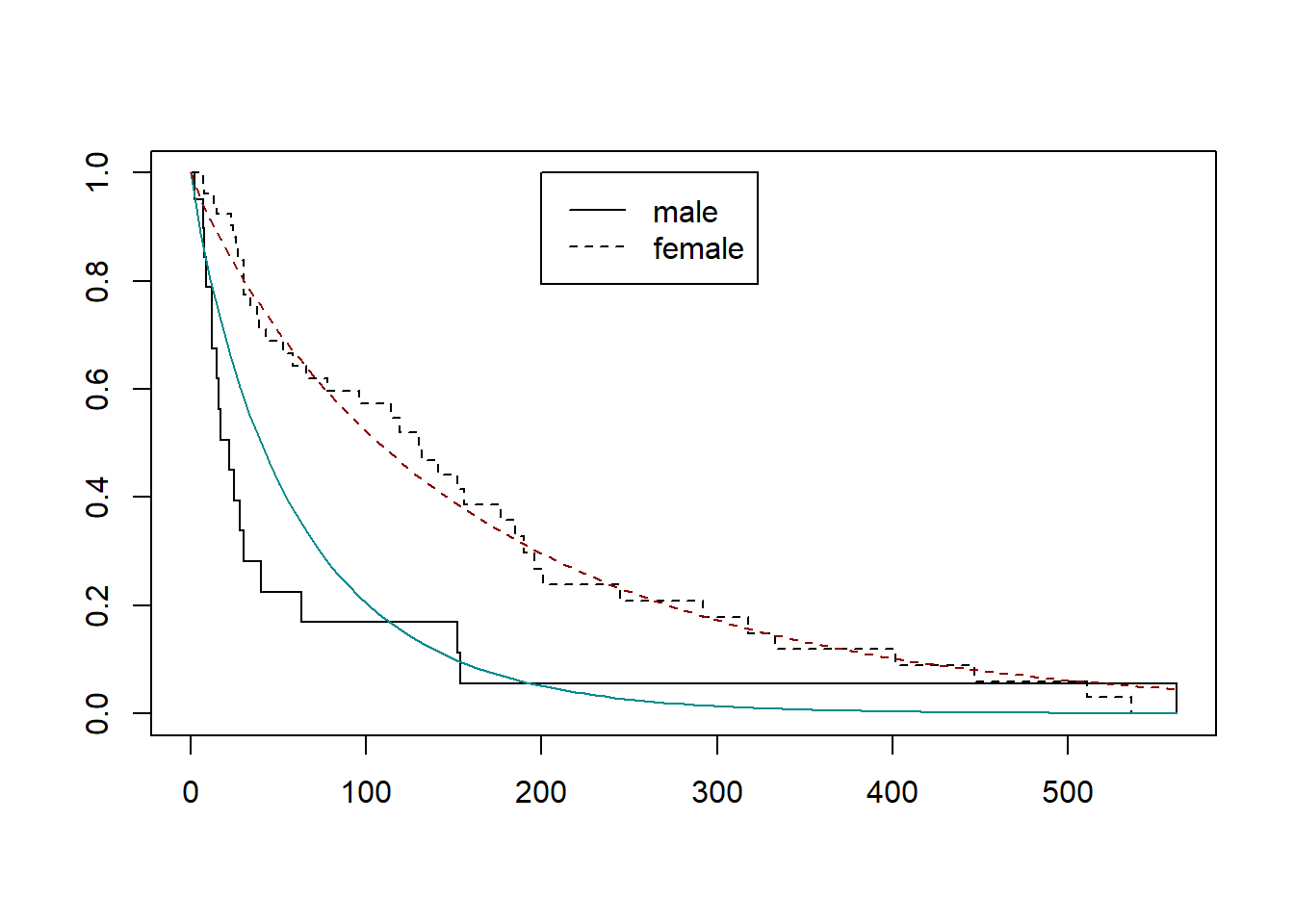
kidney.cox <- coxph(Surv(time, status) ~ age + as.factor(sex) + disease,
data = kidney)
summary(kidney.cox)Call:
coxph(formula = Surv(time, status) ~ age + as.factor(sex) + disease,
data = kidney)
n= 76, number of events= 58
coef exp(coef) se(coef) z Pr(>|z|)
age 0.003181 1.003186 0.011146 0.285 0.7754
as.factor(sex)2 -1.483137 0.226925 0.358230 -4.140 3.47e-05 ***
diseaseGN 0.087957 1.091941 0.406369 0.216 0.8286
diseaseAN 0.350794 1.420195 0.399717 0.878 0.3802
diseasePKD -1.431108 0.239044 0.631109 -2.268 0.0234 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
age 1.0032 0.9968 0.98151 1.0253
as.factor(sex)2 0.2269 4.4067 0.11245 0.4579
diseaseGN 1.0919 0.9158 0.49238 2.4216
diseaseAN 1.4202 0.7041 0.64880 3.1088
diseasePKD 0.2390 4.1833 0.06939 0.8235
Concordance= 0.697 (se = 0.041 )
Likelihood ratio test= 17.65 on 5 df, p=0.003
Wald test = 19.9 on 5 df, p=0.001
Score (logrank) test = 20.13 on 5 df, p=0.001Z <- data.frame(age = mean(kidney$age), sex = 1,
disease = levels(kidney$disease))
# 連続変数は平均値がベースラインになるように変換されている。
predict(kidney.cox, Z) 1 2 3 4
0.00000000 0.08795655 0.35079420 -1.43110776 plot(survfit(kidney.cox, Z), lty = 1:4, xlab = "age = 43.7, sex = 1")
legend(260, 1, levels(kidney$disease), lty = 1:4)